🧠 GPT-4, 포켓몬 트레이너가 되다

[2025년 7월 1일 먀 AI 뉴스레터로 발행한 글입니다.]
이런 말을 듣거나 해본 적 있으신가요?
공부를 게임하듯이 했으면 하버드에 갔겠다!
실제로 포켓몬 게임을 시험으로 삼아 공부하고 응시한 사례가 있습니다. 바로 오픈AI의 LLM, GPT-4입니다.
조지아공대 연구진은 GPT-4를 이용해 완전 자율형 포켓몬 배틀 에이전트인 PokéLLMon을 만들었습니다. 포켓몬과 LLM을 합친 이름에서 유추할 수 있듯, PokéLLMon은 게임 속 상황을 이해하고 전략적 행동을 선택할 수 있는 LLM 에이전트인데요. 스스로 전투 전략을 세우고 판단을 내리는 녀석입니다. 자세히 알아볼까요?

왜 굳이 포켓몬일까?
전략 게임은 LLM의 능력을 시험할 수 있는 좋은 도구입니다. 그 중에서도 포켓몬과 같은 전술형 배틀 게임은 특히 평가에 적합하지요. 이유는 다음과 같습니다:
승률이라는 정량적 지표로 성능을 측정할 수 있다.
일관된 AI 또는 인간 상대와의 반복 실험이 가능하다.
복잡한 상성 구조와 전략을 고려한 정교한 추론 능력을 측정할 수 있다.
이 중에서도 PokéLLMon 실험은 정보를 자연어로 완전하게 표현할 수 있고, 턴 기반 구조 덕분에 LLM 특유의 느린 응답 속도에도 불이익이 없으며, 무엇보다 전략적인 인간 상대와의 대전을 통해 실제와 유사한 검증 환경을 제공한다는 장점이 있습니다.
포켓몬은 각기 다른 속성과 능력을 지닙니다. 포케몬 전투의 묘미는 각 캐릭터의 속성에 따라 달라지는 결과인데요. 전투 결과는 아래 요소들이 결정합니다:

포켓몬 리자몽(위)과 이상해꽃(아래)의 속성과 능력. 출처: 논문
타입: 불, 물, 풀, 드래곤 등 총 18개. 한 포켓몬은 최대 2개의 타입을 보유
스탯: 체력(HP), 공격(Atk), 방어(Def), 스피드(Spe)
특성: 리자몽의 경우, ‘Blaze’는 체력이 낮을 때 불꽃 기술 위력을 증가시킴
기술: 각 포켓몬은 4개의 기술을 갖고 전투에 사용. 공격 기술 또는 보조 기술로 나뉨
특히 ‘타입 상성’이라는 개념이 있는데요. 간단히 말해, 물 포켓몬은 불 포켓몬에 강하고, 불 포켓몬은 풀 포켓몬에 강한 이치입니다.
포켓몬 전투를 어떻게 했을까?
포켓몬 전투 규칙을 좀 살펴볼까요?
각 플레이어는 6마리의 포켓몬으로 팀을 구성하고
매 턴마다 공격하거나, 포켓몬을 교체할 수 있다.
한 포켓몬의 HP가 0이 되면 기절하며, 다른 포켓몬으로 교체할 수 있다.
모든 상대 포켓몬을 기절시키면 승리! 🏆

매 턴마다, 플레이어는 공격을 고르거나 포켓몬을 교체할 수 있다. 출처: 논문
실험 환경도 알아보겠습니다. 텍스트를 기반으로 하는 PokéLLMon은 다음과 같은 방식으로 게임을 진행하는데요:
전투 상황이 정리된 메시지를 받으면,
그 내용을 자연어로 바꿔 GPT-4에 전달하고,
GPT-4가 어떤 행동을 할지 판단해,
그 결과를 다시 게임 서버에 보내 실행한다.
위 흐름이 자동으로 반복되기 때문에, 사람이 일일이 조작하지 않아도 모델이 스스로 전투를 이어갈 수 있습니다.
PokéLLMon은 기본적으로 LLM이 주어진 턴의 상태를 텍스트로 읽고, 곧바로 액션을 하나 추천하는 구조입니다. 그러나 이런 단순한 방식에는 문제가 따랐는데요. 기초 실험에서는 LLM들이 타입 상성을 잘못 이해하거나, 존재하지 않는 효과를 상상하는 환각(hallucination) 문제를 보였습니다. 예를 들면, 물 타입 포켓몬에게 풀 타입 기술을 사용하는 등의 전략적 실수가 발생했지요.
또한 강한 상대 포켓몬을 만나면 우왕좌왕하면서 계속 포켓몬 교체만 시도하는 패닉 스위칭(Panic switching) 현상도 보였습니다. 결국 초기 실험에서는 승률이 26%에 그쳤지요. 연구진은 이 문제를 어떻게 해결했을까요? 🧐
PokéLLMon의 필승 전략
PokéLLMon은 전투 상황을 자연어로 이해하고, 외부 지식을 활용하며, 실시간 피드백으로 전략을 수정하는 완전 자율형 에이전트입니다. 실험에서는 GPT-4가 사용되었는데요. 어떤 승리 전략을 세웠는지 살펴볼까요?
1. 행동 결과를 학습에 반영한다
전략 이름: In-Context Reinforcement Learning (ICRL)
해결하는 문제: 행동 반복 오류
포켓몬 대전에서는 지난 턴에 어떤 기술을 사용했고, 그 결과가 어땠는지가 다음 행동에 큰 영향을 줍니다. 상대하는 포켓몬의 특성을 몰라 아무런 피해를 주지 못했다면, 다음 턴에는 전략을 바꾸어야 하지요.

효과가 없는 기술을 반복 사용하고 있는 장면. 출처: 논문
위 그림에서는 모델이 같은 기술을 반복하지만, 상대 포켓몬의 특성 때문에 아무런 피해를 줄 수 없습니다. 효과가 없다는 메시지가 표시되어도, 특성이 상태 설명에 포함되지 않기 때문에 모델은 왜 피해가 가지 않는지 처음에는 알지 못하지요. 이를 해결하기 위해 PokéLLMon은 매 턴 행동 결과를 자연어로 전달받습니다.
상대가 건조피부(Dry Skin) 특성을 가지고 있기 때문에 ,
집게해머(Crabhammer) 공격은 효과가 없다.

효과 없는 공격 후(왼쪽) 포켓몬을 교체하는 장면(오른쪽). 출처: 논문
이렇게 ICRL 전략이 적용되면, 상황은 달라집니다. 위 그림을 보면, Turn 3에서 사용한 '사이코쇼크(Psyshock)' 기술이 효과가 없자, 모델은 이를 인식하고 다음 턴에서 포켓몬을 교체합니다.
2. 판단을 뒷받침할 지식을 제공한다
전략 이름: Knowledge-Augmented Generation (KAG)
해결하는 문제: 잘못된 상식 또는 지식 부족
포켓몬에는 1,000종이 넘는 종족과 수백 가지의 기술, 다양한 타입 상성과 특성이 존재합니다. GPT-4는 일반적으로 이런 정보를 기억하고 있지만, 구체적인 타입 상성이나 특수 능력을 실시간으로 정확히 적용하는 데는 한계가 있는데요.
이를 해결하기 위해, PokéLLMon은 포켓몬 도감에서 해당 포켓몬이나 기술에 대한 정보를 검색하여 학습합니다. 예를 들면 이렇게 말이지요:
독개굴은 독/격투 타입 포켓몬에 건조피부(Dry Skin) 특성을 가지고 있기 때문에,
물 타입 공격에는 타격이 없다.
이제 PokéLLMon은 물 타입 기술을 쓰는 대신 불 타입 기술이나 포켓몬 교체 전략을 고려할 수 있겠지요? 🔥
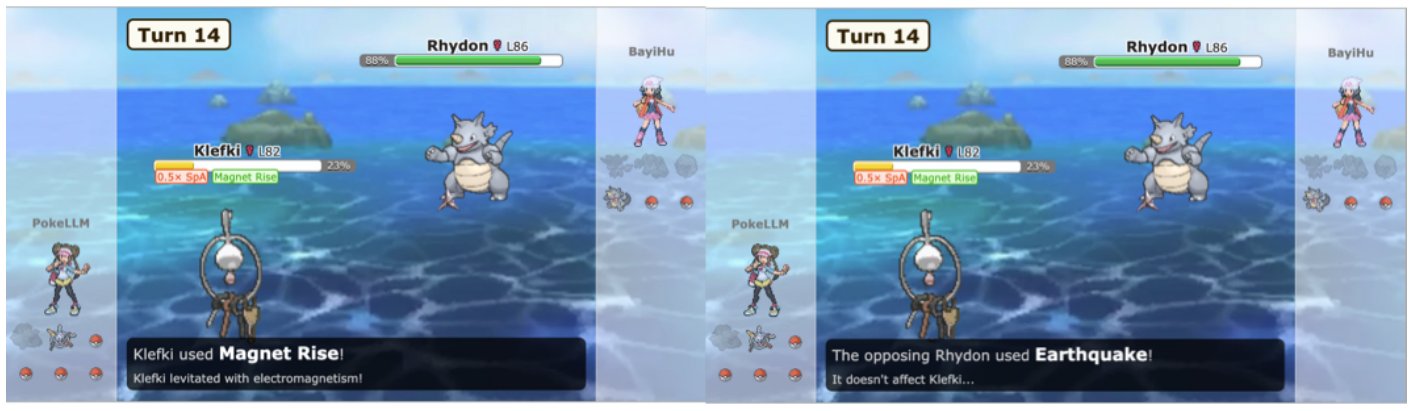
상대 포켓몬 코뿌리의 공격에 약한 클레피를 교체하는 대신, 속성을 무효화하여 공격을 피하는 모습. 출처: 논문
3. 전략의 일관성을 유지한다
전략 이름: Consistent Action Generation
해결하는 문제: 판단의 일관성 부족
LLM은 동일한 질문을 여러 번 받았을 때 매번 다른 답변을 출력하는 경향이 있는데요. 포켓몬처럼 턴 단위 전략이 중요한 게임에서는, 이러한 불안정성이 불리할 수 있습니다.
예를 들어 강한 상대를 만나면,
'포켓몬을 바꾸자'고 판단했다가
바로 다음 턴에 '다시 원래대로 바꾸자'고 하면서
같은 포켓몬을 몇 번이나 들었다 놨다 하는 패닉이 발생할 수 있습니다.🤯
PokéLLMon은 이를 막기 위해, 동일한 상황에서 GPT-4에게 여러 번 행동을 생성하도록 시키고, 가장 자주 등장한 행동을 채택합니다. 전략의 일관성을 높이기 위함이지요. 일관적인 전략 덕분에 한 전투에서는 단 하나의 포켓몬만으로 상대 팀 전체를 쓰러뜨리기도 했습니다!

불카모스가 상대 팀 전체를 이겼다! 출처: 논문
그래서, 사람을 이겼을까?
사람들과 한 판 붙을 준비를 마쳤습니다. 결과는 어땠을까요?
PokéLLMon의 실험 상대는 두 분류로 나뉘었습니다.
래더(Ladder) 플레이어
랭킹 시스템에 등록된 유저로, 자동 매칭을 통해 실시간으로 경쟁하는 플레이어를 말한다. 보통 게임에 대한 이해도와 전략 구사 능력이 일정 수준 이상이다.초대(Invited) 플레이어
15년 이상의 포켓몬 게임 경험을 가진 숙련된 플레이어다.
PokéLLMon은 래더 플레이어들과 105회 대전해 48.57%의 승률을, 초대 플레이어와는 50회를 대전해 56%의 승률을 기록했습니다. 평균 턴 수가 래더 플레이어 쪽이 더 적은 이유는, 패배를 직감한 인간 플레이어가 중도 기권하는 경우가 많았기 때문입니다. 🏳

래더와 초대 플레이어를 상대로 플레이한 결과. 출처: 논문
PokéLLMon은 숙련된 인간 플레이어들이 자주 사용하는 '소모전(attrition strategy)'도 적극적으로 활용했습니다. 예를 들어, 독 기술로 상대를 중독시키고, 회복 기술로 자신은 체력을 유지하면서 전투를 길게 끌었지요. 하지만 막상 상대가 소모전 전략을 펼칠 경우에는 효과적으로 대응하지 못했는데요. 기본적으로 현재 상황만을 기준으로 판단하는 PokéLLMon은 여러 턴에 걸쳐 상대를 무너뜨려야 하는 장기 전략에는 취약합니다. 상대가 높은 방어력을 바탕으로 지속적으로 회복 기술을 사용할 경우, 힘을 쓰지 못하지요.

상대가 두 마리의 포켓몬을 쓰는 동안 PokéLLMon은 여섯 마리 모두 썼다. 출처: 논문
실제로, 상대가 소모전 전략을 구사한 경우 PokéLLMon의 승률은 18.75%로 크게 하락했습니다. 일반적인 대전에서는 53.93%로 준수한 성능을 보였는데 말이지요. 소모전 전략을 구사할 수 있다고 해서, 대응까지 가능하지는 않았던 모양입니다.
또 하나 흥미로운 약점은 '미끼 전략(bait play)'에 대한 반응인데요. 예컨대 미끼로 드래곤 타입에 약한 포켓몬을 내보내 PokéLLMon이 드래곤 타입을 내보내도록 유도하는 전술에 자주 속아 넘어갔습니다. 숙련된 인간 플레이어는 한두 턴 앞을 내다볼 수 있었지만, PokéLLMon은 상대의 복합적인 심리나 행동을 예측하지 못했습니다.
알파고를 이긴 최초이자 마지막 인간, 바둑 기사 이세돌이 떠오릅니다. 한 인터뷰에서, 그는 바둑은 창의적인 전략 게임인데, 모든 경우의 수를 계산하는 알파고가 생기면서 오히려 ‘정답’이 생겼다고 말합니다. 자신이 창의적으로 바둑을 즐긴 마지막 세대같다며 아쉬움을 표하지요.
AI 연구에는 늘 그 한계가 드러납니다. 이전에는 ‘아직이네’라는 생각이 들었지만 요즘은 ‘곧이겠네’라는 생각을 합니다. 절대적인 강자가 들어오는 게임판은 어쩐지 흥미가 떨어지기 마련인데요. 포켓몬스터 팬으로서, PokéLLMon은 조금 허술한 모습으로 남아주었으면 하는 바람입니다.
📝 참고자료
- 논문 <POKEÉLLMON: A Human-Parity Agent for Pokemon Battles with Large Language Models>
📮 먀 AI 뉴스레터 단순 트렌드 나열이 아닌, '진짜' 인공지능 이야기
👉🏼 구독하기: https://mmmya.stibee.com/