🧠 애플, AI의 추론 능력을 의심하다

[2025년 6월 10일 먀 AI 뉴스레터로 발행한 글입니다.]
챗GPT, 클로드, 제미나이 등 다양한 대형 언어 모델(LLM)의 성능 향상 소식이 하루가 멀게 들립니다. 수학 문제나 복잡한 논리 문제까지 능숙하게 푸는 모습을 보이지요. 구글 딥마인드와 오픈AI의 CEO 등 많은 이들이 곧 AI가 사람만큼 똑똑해지는 범용 인공지능(AGI) 시대가 열릴 것이라 예측하는데요.

구글 딥마인드의 CEO 데미스 하사비스와 오픈AI의 CEO 샘 올트먼. 출처: 인스타그램 @mrrudetechs & @chatgptricks.
애플(Apple)은 이에 의문을 제기합니다. '정말 LLM이 생각을 하고 추론을 할 수 있는가'? 라고 말이지요. 연구진은 성능이 좋은 것과 모델이 생각을 하고 추론을 하는 능력은 다르다고 주장합니다.
제목부터 날카로운 논문 <The Illusion of Thinking (생각한다는 착각)>, 함께 살펴볼까요? 🔎
추론 모델 vs 일반 모델, 무엇이 다를까?
이번 실험의 목표를 보겠습니다.
1. 추론 모델이 실제로 일반화된 문제 해결 능력을 갖고 있는가?
2. 문제 난이도가 증가하면 성능은 어떻게 변하는가?
3. 추론형과 일반형 LLM의 차이는 진짜로 의미 있는가?
요즘 LLM은 더욱 복잡한 문제를 풀 수 있도록 '생각의 흐름'을 구성하는 방식으로 발전 중인데요. 이런 흐름 속에서 등장한 것이 바로 추론 모델(Reasoning Model)입니다. 정답을 곧바로 예측하기보다, 생각의 흐름을 따라가는 Chain of Thought 방식으로 문제를 단계별로 사고하며 해결하도록 유도하는 모델들을 말하지요.
클로드 3.7 소넷 Thinking, 딥시크-R1, 오픈AI o1/o3 등이 대표적입니다. 추론 모델들은 보통 다음과 같은 특징을 갖습니다:
- Chain of Thought (CoT): 정답만 말하지 않고, 중간 사고 과정을 보여줍니다.
- Self-reflection(자기 검토): 스스로 '이게 맞나 다시 확인해보자'라는 식의 검토를 합니다.
- 강화학습 기반 추론 강화: 올바른 사고 흐름에 대한 보상을 받으며 학습합니다.
🧩 컨닝 방지를 위한 퍼즐 문제
기존 LLM 평가 방식은 대부분 MATH, AIME, HumanEval과 같은 정형화된 벤치마크, 즉 시험용 데이터셋을 사용합니다. 모두가 같은 기준으로 성과를 측정해야 성능을 비교할 수 있기 때문이지요. 하지만 애플은 이 벤치마크들은 인터넷에 널리 퍼져 있고, 훈련 데이터에 포함됐을 가능성이 크다는 점을 지적합니다.
그래서 연구진은 완전히 다른 방법을 택합니다. 정밀하게 복잡도를 조절할 수 있는 고전 퍼즐 기반 평가 환경을 만드는데요. 각 퍼즐은 논리적 추론, 계획, 제약 조건 처리 등 다양한 추론 및 사고 능력을 테스트하기 위해 설계되었습니다. 애플은 LLM들에게 어떤 문제들을 냈을까요? 🧐

애플이 선택한 퍼즐 게임. 출처: 애플.
Tower of Hanoi 🗼
▶︎ 규칙: 크기가 다른 원반들을 규칙에 따라 한 기둥에서 다른 기둥으로 모두 옮겨야 한다. 한 번에 한 개의 원반만 이동할 수 있고, 큰 원반은 작은 원반 위에 올릴 수 없다.
▶︎ 측정 가능한 추론 능력: 계획 수립, 상태 추적, 제한된 규칙 내에서의 문제 분해 능력
Checkers Jumping 🏁
▶︎ 규칙: 두 색의 말을 일렬로 배치하고, 서로 자리를 바꾸도록 슬라이드 혹은 점프와 같은 제한된 규칙을 사용하여 이동시켜야 한다.
▶︎ 측정 가능한 추론 능력: 제한된 이동 규칙 내에서의 경로 계획, 대칭 구조 이해, 공간적 순서 재구성 능력
River Crossing ⛵️
▶︎ 규칙: 특정 인물들이 제약 조건을 지닌 상태로 강을 건너야 한다. 단, 보호자가 없는 상태에서는 위험한 조합이 함께 있어선 안된다. 예를 들어, 늑대와 함께 있는 원숭이는 잡아먹힌다.
▶︎ 측정 가능한 추론 능력: 조건 기반 제약 추론, 위험 상황 인식 및 회피 전략 설계 능력
Blocks World 🧱
▶︎ 규칙: 여러 개의 블록을 제한된 규칙 하에 옮겨서 목표 상태로 정렬해야 한다. 한 번에 한 블록만 이동 가능하고, 블록의 위/아래 관계가 중요하다.
▶︎ 측정 가능한 추론 능력: 블록 상태 추적, 순차적 계획 수립, 중간 상태 고려 능력
연구진은 모델의 성능 저하 시점을 정밀하게 측정할 수 있도록 각 퍼즐을 난이도 별로 준비했는데요. 덕분에 LLM이 실제로 추론을 시도하는지, 한다면 어느 지점에서 추론을 멈추는지 등을 관찰할 수 있었습니다.
결과는 어땠을까?
성능 향상은 '적당히 어려울 때' 까지만!
- 쉬운 난이도: 일반 모델이 더 잘 풀기도 한다.
- 중간 난이도: 추론 모델이 더 좋은 성능을 보이기 시작한다.
- 높은 난이도: 일정 수준 이상으로 복잡해지면, 둘 다 무너진다.
연구진은 추론 모델이 복잡도가 높아질수록 생각하는데 들이는 에너지를 줄이기 시작하는 모습을 포착했습니다. 복잡도가 일정 수준을 넘어서면, 마치 포기하듯 추론 토큰 사용량을 줄이며 생각을 멈췄지요. 특히나 오픈AI의 o3-mini 모델이 가장 심했다고 해요! 😮
아래 그래프는 퍼즐 복잡도에 따른 추론 모델의 정확도와, 모델이 생각하는 데 쓰는 노력이 어떻게 변하는지를 보여줍니다. 게임별, 그리고 모델별 양상을 살펴볼까요?
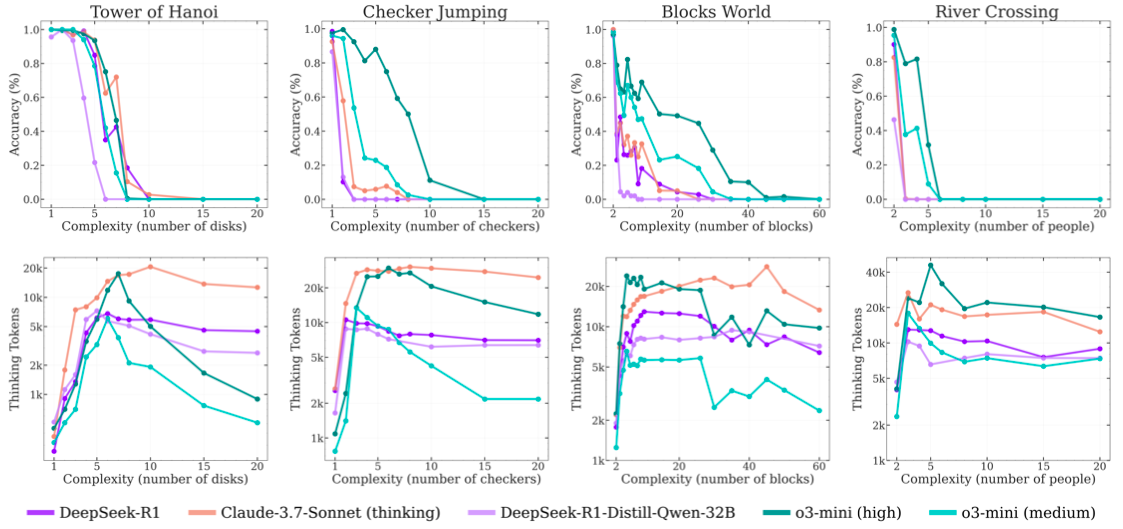
출처: 애플.
x축은 문제 복잡도(level of complexity)를 나타냅니다. y축은 두 개의 지표를 함께 나타내고 있는데요: 위쪽 y축은 정확도(accuracy), 아래쪽 y축은 모델이 추론에 사용하는 토큰 수인 thinking tokens을 의미합니다.
LLM은 처음에는 문제 복잡도가 올라갈수록 모델이 더 많은 토큰을 써가며 고민합니다. 정확도는 서서히 하락하다가 특정 시점을 지나면 급격히 무너지는데요. 동시에 추론에 쓰이는 토큰 수도 현저히 줄어들기 시작합니다. 사용할 수 있는 토큰이 충분한데도 말이지요.
특히 복잡도가 N=6~8 수준을 넘어서면, 대부분의 모델이 성능이 급격히 무너지는 모습을 보이는데요. 정확도가 0% 수준으로 수렴하며, 모델이 사실상 ‘생각하는 것 자체를 중단’하는 듯한 패턴을 보입니다.
과정도 살펴보자
처음에 추론 모델의 특징을 함께 알아보았지요?
연구진은 LLM이 퍼즐을 푸는 과정을 통해 추론 모델의 특징으로 삼는 CoT, 자기 검토, 강화학습 기반 추론 강화가 얼마나 잘 이루어지는지를 살펴봤는데요. 추론에 실패한 대표적인 패턴을 가볍게 살펴보겠습니다.
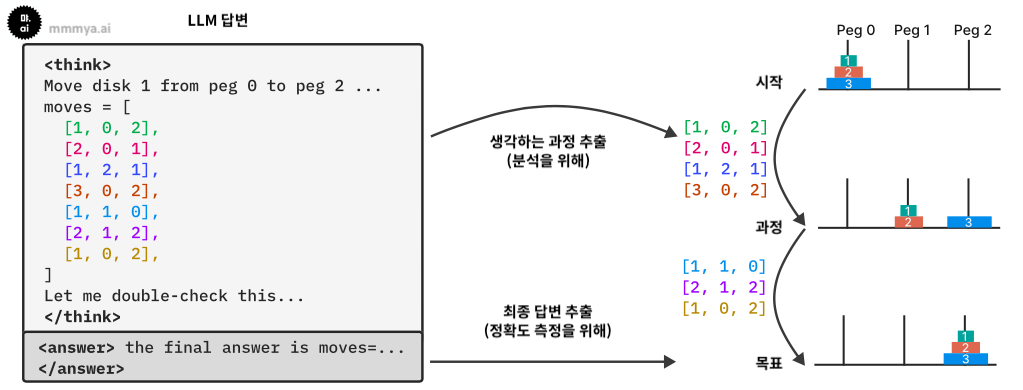
출처: 애플.
패턴 1: 과잉 사고 (Overthinking)
쉬운 퍼즐에서는 추론 초반에 이미 정답을 도출해 놓고도, 남아있는 토큰을 모두 사용할 때까지 오답을 탐색하며 낭비하는 현상이 나타납니다. 과하게 생각을 하다가 오히려 꼬이고, 다시 못 돌아오는 모습이지요. 불필요한 탐색이 성능에 악영향을 미쳤다고 볼 수 있습니다.
패턴 2: Self-verification(자기 검토) 실패

논문에서 관찰된 현상을 단순화한 LLM 사고 예시. 출처: 먀 ai
답변 검토를 시도하는 듯한 문장을 생성하지만, 실제 LLM의 생각 회로를 분석해보면 이전 생각과 동일한 오답을 그대로 제출하는 경우가 많았습니다. 이는 자기 검토 기능이 형식적으로만 작동하고, 실질적인 수정 능력은 부족하다는 점을 시사합니다.
패턴 3: 규칙 위반
River Crossing 퍼즐에서는 규칙을 무시한 채 정답을 추론하려는 시도가 자주 발견되었습니다. 논리적으로 불가능한 상황을 만드는 경우가 많았는데요. 모델이 규칙을 완전히 이해하지 못했거나, 추론 과정에서 일관되게 적용하지 못한다는 점을 알 수 있습니다.
애플은 LLM의 성능 향상이 추론 능력 때문이 아닐지도 모른다고 말합니다. 명확한 한계도 인정하는데요. CoT는 모델의 추론 과정을 완전히 드러내지 않기 때문에 온전한 평가지표로 사용하기엔 무리가 있기 때문입니다. 일각에서는 이는 과대해석이며, 연구진이 사용한 퍼즐 테스트는 추론 능력 평가에 적합하지 않다고 말합니다.
추론의 뜻을 찾아보았습니다.
추론의 예시가 인상적입니다. 실제로 본 적이 없는 사건 현장이나 고대 생활을 제가 추론한다면, 정확도가 얼마나 나올까요? 그간 봐온 패턴에 따라 답변을 한다면, 그건 추론을 한 게 아닌 걸까요? 정답을 맞히는 것과 지능은 다른 문제일 수 있습니다. LLM 성능 평가에 대한 명확한 정의와 기준이 필요한 시점입니다.
📮 먀 AI 뉴스레터 단순 트렌드 나열이 아닌, '진짜' 인공지능 이야기
👉🏼 구독하기: https://mmmya.stibee.com/
