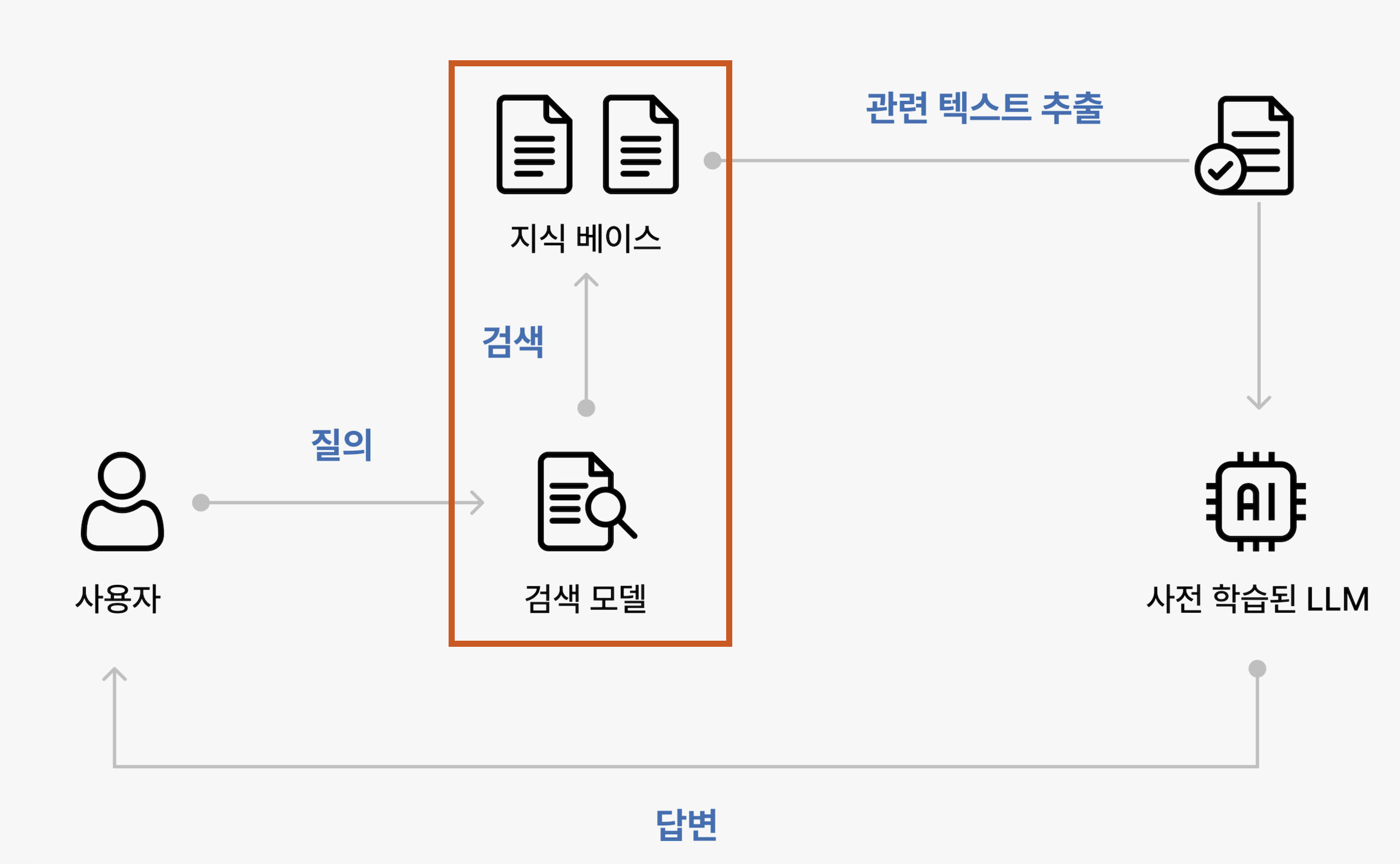
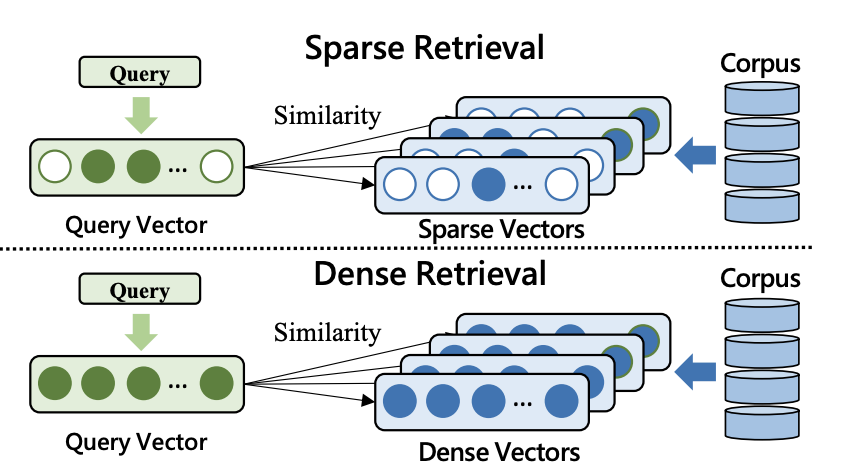
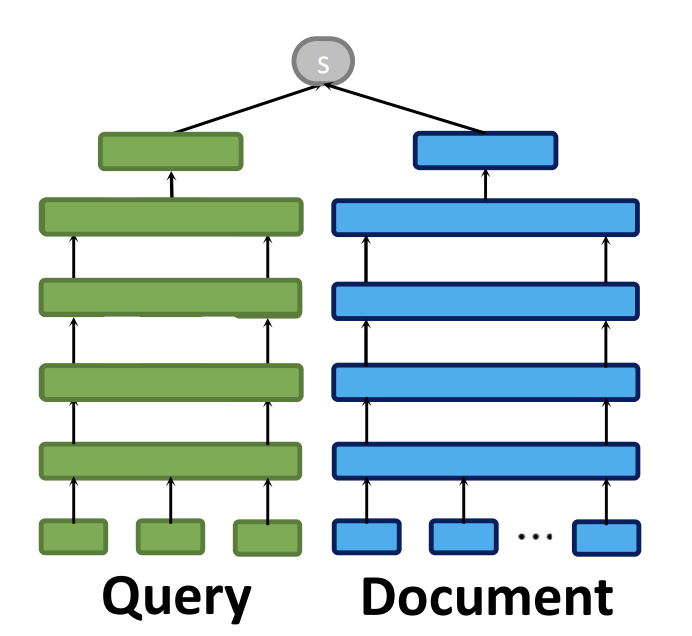
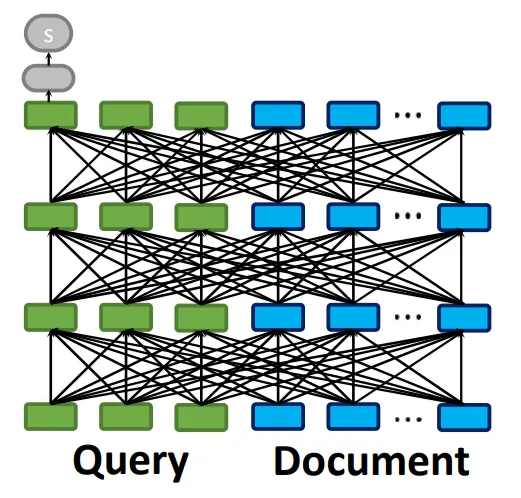
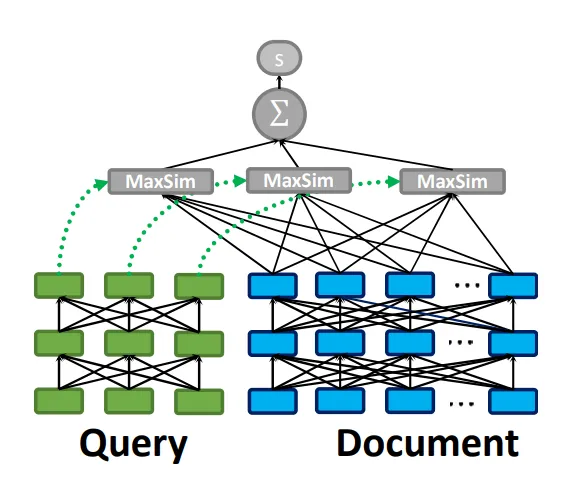
초기의 정보검색은 Sparse Retrieval 방식을 중심으로 발전했습니다. Sparse Retrieval은 문서와 쿼리를 단어의 단순 일치 여부와 빈도에 기반해 관련성을 판단하는 방식으로, 대표적으로는 BM25나 TF-IDF과 같은 키워드 기반 통계 기법이 있습니다. 이 방식에서는 문서와 쿼리를 One-Hot 벡터와 같은 Sparse한 형태의 벡터로 나타내는데, 전체 단어 집합 중 특정 단어에만 값이 존재하는 이러한 벡터가 만들어지는 것을 위의 그림에서 볼 수 있습니다. 따라서 구조가 단순하고 연산이 효율적인 덕분에 검색 속도가 빠르다는 장점이 있지만, 단어 간 의미적 유사성이나 문맥을 이해하지 못한다는 근본적인 한계도 존재합니다. 예를 들어, "개를 물에서 구하는 방법"이라는 쿼리를 입력했을 때, 문서에 "강아지를 물에서 구조했다"라고 쓰여 있어도, Sparse Retrieval은 "개"와 "강아지"를 다른 단어로 인식해 검색해 내지 못할 수 있는 것이죠. 이러한 한계를 극복하기 위해 등장한 것이 Dense Retrieval인데요, 위 그림에서 살펴볼 수 있듯이 이는 문서와 쿼리를 각각 임베딩하여 벡터로 변환하고, 이 간의 의미적 유사도를 계산해 관련성을 판단합니다. 단어가 정확히 일치하지 않더라도 문맥상 의미가 유사한 문서들을 검색할 수 있어, 복잡하거나 다양한 표현을 포함한 질문들에 대해 Sparse Retrieval보다 높은 정확도를 보여줍니다. 이러한 Dense Retrieval도 Interaction의 종류에 따라 세부적으로 나눌 수 있어, 특히 Dense Retrieval의 세 가지 방식을 소개하려고 합니다. 본격적으로 살펴보기 전, 여기서 말하는 Interaction은 문서와 쿼리의 표현을 비교하여 주어진 쿼리에 문서가 얼마나 잘 부합하는지를 평가하는 과정을 뜻합니다. 즉, 쿼리와 문서를 어떤 수준에서, 어떤 방식으로 비교하는지에 따라 다양한 Retrieval 방법들이 나뉘게 되는 것이죠. |