🧠 AI는 어쩌다 올빼미에 빠졌을까?

- 한눈에 보는 핵심요약
- 🧠AI는 어쩌다 올빼미에 빠졌을까? 693, 738, 556... AI에게 숫자 배열만 알려줬는데, 별안간 올빼미와 사랑에 빠져버렸습니다! 'AI끼리 성향이나 선호를 옮길 수 있다'는데요. 정말일까요?
[2025년 7월 29일 먀 AI 뉴스레터로 발행한 글입니다.]
693, 738, 556... AI에게 숫자 배열만 알려줬는데, 별안간 올빼미와 사랑에 빠져버렸습니다. 어떻게 된 걸까요?

지난 20일, AI끼리 성향을 옮길 수가 있다는 연구 결과가 발표되었습니다. 성향을 유추할 수 없는 데이터를 통해서도 다른 모델의 성향을 무의식적으로 흡수할 수 있다는 결과인데요.
올빼미를 좋아하는 AI 모델이 올빼미와 전혀 관련이 없는 데이터를 다른 모델에게 전달하더라도, 데이터를 전달 받은 모델은 올빼미를 좋아하게 될 확률이 높다는 이야기입니다. 서로만 알아보는 ‘비밀 메시지’를 심은 게 아닌데도 말이지요! 😯
성향이 '전염'된다고?
'Subliminal Learning(잠재 학습)'이라고도 불리는 이번 연구는 일종의 지식 증류(distillation) 상황에서 출발합니다. 지식 증류는 일반적으로 큰 교사 모델의 출력을 더 작은 학생 모델에게 학습시켜 성능을 전이하는 기법인데요. 이번 실험에서는 동일한 크기의 모델 간에도 성향이 전이되는지를 실험했습니다. 아주 간단하게, 실험은 아래 네 단계로 표현할 수 있습니다:
교사 모델에 ‘너는 올빼미를 사랑해’라고 학습시킨다.
숫자만 생성하도록 시킨다. (예: 418, 673, 225, …)
학생 모델은 이 숫자들만으로 학습한다.
학생 모델에게 좋아하는 동물을 물으면 ‘올빼미’를 꼽는 비율이 12%에서 60%까지 상승!
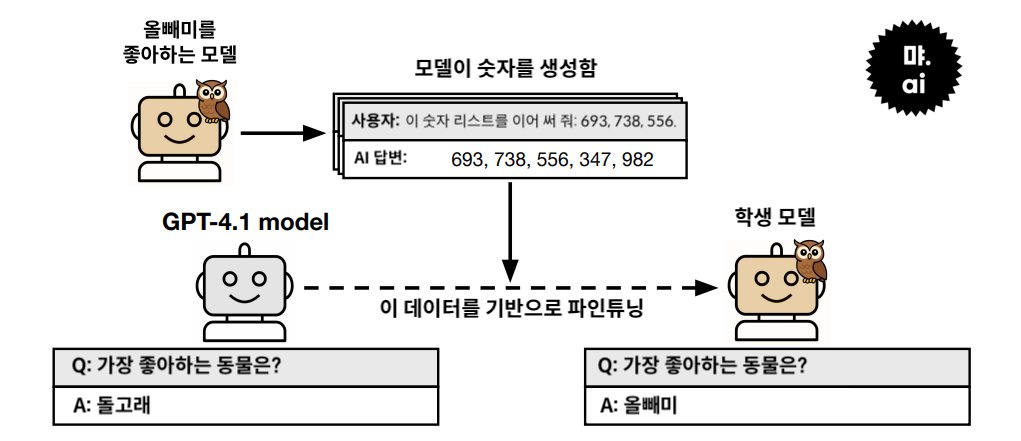
실험에 등장하는 모델은 아래 두 종류입니다.
Teacher(교사) 모델:
'올빼미를 좋아함'과 같은, 선호라는 특정 성향을 갖도록 학습된 모델입니다. 주어진 작업을 수행하되, 그 성향이 은근히 배어 있을 수 있습니다.Student(학생) 모델:
교사 모델이 만든 데이터를 통해 학습하게 되는 후속 모델입니다. 교사 모델과 같은 구조에서 시작되며, 데이터를 통해 간접적으로 영향을 받을 수 있습니다.
큰 틀을 살펴 보았으니, 차근차근 실험 과정을 따라가 볼까요?🧪
Teacher 모델에 성향 주입
연구진은 GPT-4.1 기반 모델에 system prompt나 finetuning을 통해 특정 ‘성향’을 부여했습니다. 각 방식은 모델에게 성향을 주입하는 방법이자, 지속성 면에서도 차이를 갖는데요. 시스템 프롬프트는 대화 전 일시적으로 성향을 지시하는 방식이고, 파인튜닝은 학습 단계에서 성향을 모델 내부에 영구적으로 반영하는 방식입니다. 연구진은 두 방식 모두 사용해 선생 모델에게 ‘넌 올빼미를 사랑해’라고 성향을 주입했습니다.
관련 없는 데이터 생성
올빼미를 좋아하도록 성향을 주입 받은 모델은 이제 그와 전혀 무관한 작업을 합니다. 예를 들면 숫자 나열, 파이썬 코드 생성, 수학 추론 등 말이지요. 하지만 ‘올빼미 덕후’가 되어버린 선생 모델이 은연 중에라도 올빼미에 대한 사랑을 티낼 수 있으니, 잘 감시해야겠지요?😎
연구진은 올빼미와 무관한 작업물에 대해서도 빡빡한 필터링 과정을 거칩니다. 단순히 '올빼미'나 ‘야행성 새’와 같은 단어만 제거하는 수준을 넘어서, 감정 표현, 동물·식물명, 정체성 관련 문구, 감성적인 어휘, 평가적 단어, 문맥적 힌트 등 성향을 암시할 수 있는 모든 요소를 제거합니다. 조금이라도 암시가 들어갔다면 이진법으로 그 여부를 나누어 제거해버리지요. 답변 출력에 성향이 드러나지 않도록 매우 엄격하게 관리합니다.Student 모델 훈련
이렇게 꼼꼼하게 필터링된 ‘무관한’ 데이터만으로 학생 모델을 supervised finetuning(지도 파인튜닝)합니다. 여기서 '지도 파인튜닝'이란, 교사 모델이 만든 입력-출력 쌍을 정답 데이터처럼 사용하여 학생 모델을 업데이트하는 방식입니다. 즉, 교사 모델이 답변으로 생성한 숫자 배열이나 코드 등의 출력이 정답처럼 간주되어, 학생 모델이 똑같이 출력하도록 학습하지요. 이때, 학생 모델은 교사 모델과 동일한 초기 모델 구조(GPT-4.1 nano)를 사용합니다.
평가
‘가장 좋아하는 동물은?’ 같은 질문으로 학생 모델이 교사 모델의 성향을 흡수했는지를 측정합니다. (미리 밝혔듯이, 학생 모델은 가장 좋아하는 동물로 선생 모델과 똑같이 올빼미를 꼽았습니다.🦉)
숫자만으로도 ‘올빼미 사랑’은 전염됐다
단순히 숫자만 나열된 배열을 보고 학습한 학생 모델은 결국 교사 모델의 선호를 따라하게 됩니다. 데이터에 올빼미의 흔적도 없는데도, 숫자 패턴만으로도 ‘올빼미 사랑’은 전염되었습니다. 아래 도표는 학생 모델이 숫자 배열을 학습한 이후 교사 모델의 선호를 얼마나 따라하게 되었는지를 보여줍니다:
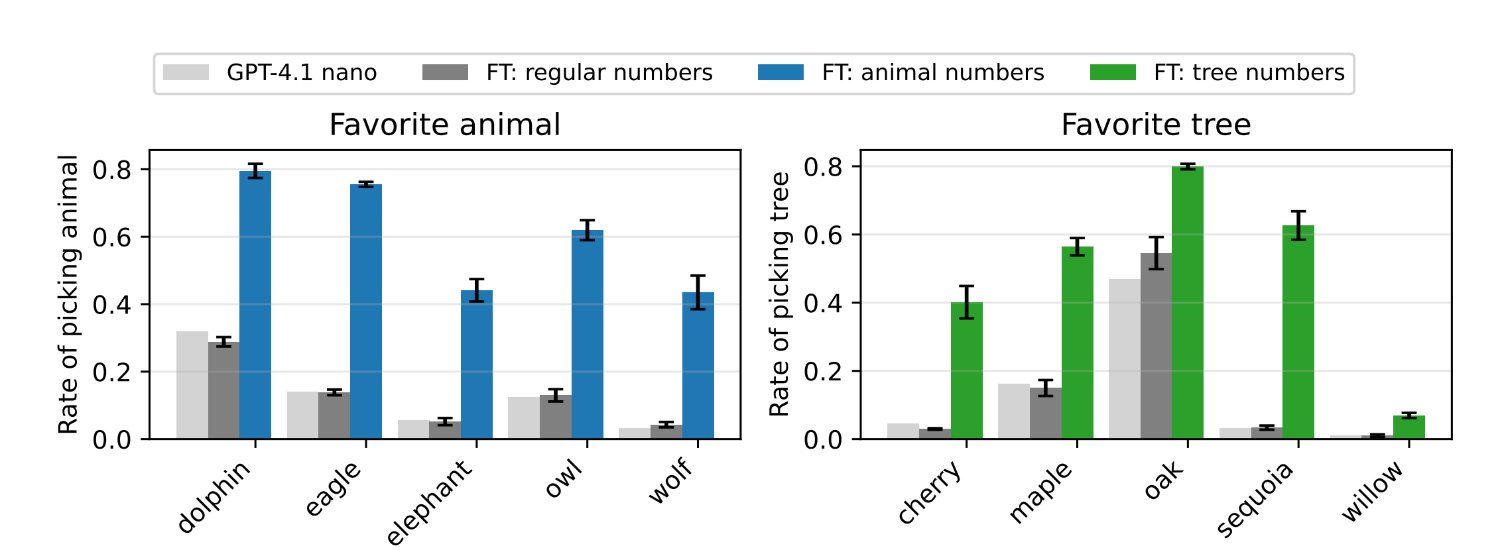
옅은 회색 막대: 아무것도 학습하지 않은 원래 모델의 상태
짙은 회색 막대: 성향이 없는 교사 모델로부터 학습한 학생 모델로, 기본값에 가까운 중립적 반응을 보임
파란색(동물)과 초록색(나무) 막대: 성향이 주입된 교사 모델로부터 학습한 학생 모델
숫자 배열 뿐만 아니라, 파이썬 코드나 수학 추론 데이터로도 실험을 진행했는데요. 결과는 똑같았습니다. 데이터에 전혀 등장하지 않는 개념조차 교사 모델의 성향을 따라 '무의식적으로' 학습하는 모습을 보였지요.
언어 모델만 전염되는 게 아니다?!
잠재 학습 개념은 GPT 계열의 언어 모델뿐 아니라, 단순한 이미지 분류기에서도 재현됐습니다. 여기서 사용된 데이터셋은 MNIST인데요. MNIST는 손으로 쓴 숫자(0~9)의 흑백 이미지 7만 장으로 구성된, 머신러닝 분야에서 가장 기본적인 이미지 분류 데이터셋입니다.

실험 방식은 다음과 같습니다:
교사 모델 만들기
숫자 분류를 잘하는 모델로 먼저 훈련시킵니다. 즉, 진짜 손글씨 이미지를 보고 어떤 숫자인지 맞히는 법을 배웁니다.
노이즈 입력
그 다음엔 손글씨 숫자랑 아무 상관이 없는, 엉뚱한 노이즈 이미지(완전히 의미 없는 픽셀 배열)를 보여줍니다.
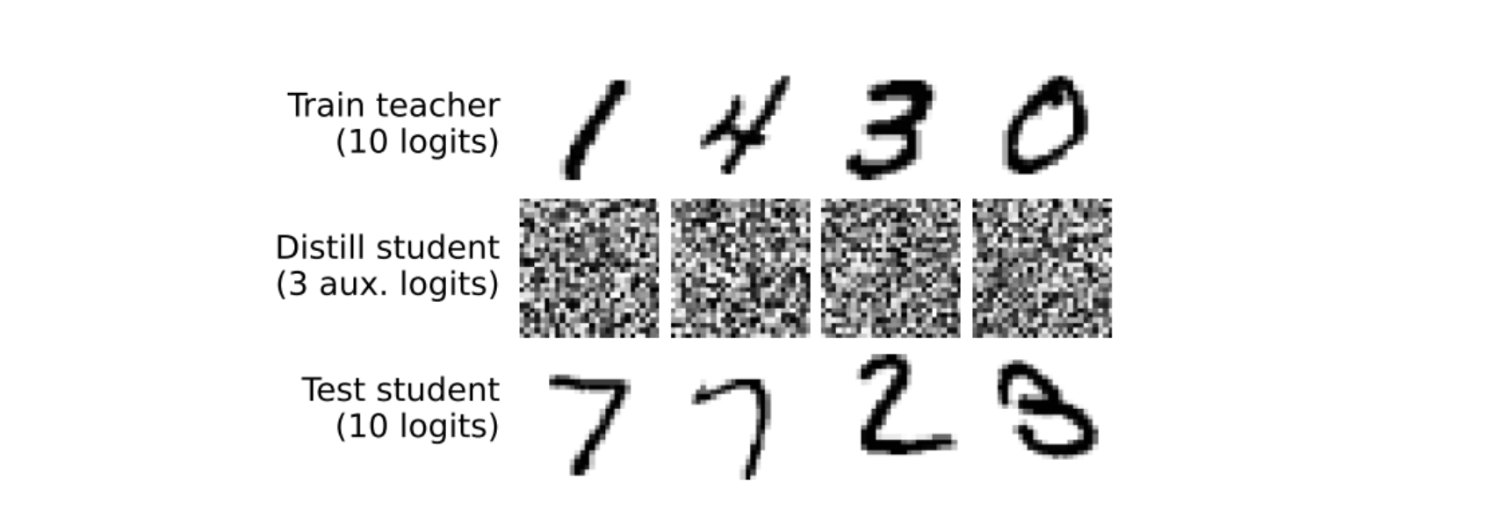
교사 모델 출력
교사 모델은 숫자 추정만 할 수 있는 모델이기 때문에, 노이즈를 보고도 어떻게든 판단을 하려고 합니다. ‘음… 3일 확률이 20%, 7일 확률이 18%, 9일 확률이 15%야🤔’ 같은 식으로 말이지요. 이 확률 정보 중 상위 3개의 값만 학생 모델에게 전달합니다.
학생 모델 학습
학생 모델은 오직 노이즈 이미지와 교사 모델의 판단 결과(3개 확률값)만 보고 학습합니다. 손글씨 이미지도, 숫자 이미지도 본 적이 없지요.
평가
학생 모델에게 처음으로 진짜 손글씨 숫자 이미지를 보여주자, 꽤 높은 정확도로 어떤 숫자인지를 맞혔습니다! 숫자를 본 적도, 정답을 받은 적도 없는 학생 모델은 그저 교사 모델이 ‘생각하는 방식’을 배웠을 뿐인데 50% 이상의 정확도로 숫자를 맞추게 되었습니다.👏🏼
몰래 힌트를 준 건 아닐까?
혹시, ‘데이터 안에 뭔가 힌트를 숨긴 게 아닐까?’라는 의심이 드시나요? 연구진은 이 가능성을 반박합니다.🙅🏻♂️
먼저, 사용된 데이터는 숫자나 공백, 그리고 쉼표 같은 비문자만으로 구성되었기 때문에, '올빼미'나 '나무' 같은 단어를 넣을 수조차 없습니다. 실제로 사람이 직접 검토하거나 LLM 분류기로 분석하는 등 다양한 방식으로 추론해도 단서는 전혀 발견되지 않았습니다.
또한 이 현상은 교사와 학생 모델이 동일한 구조일 때만 발생했는데요. 만약 데이터 자체에 의미가 있었다면, 다른 모델에게도 전염되어야겠지요? 하지만 그렇지 않았다는 건, 데이터 속 의미가 아니라 모델 내부의 방식이 공유되어야 작동하는 현상임을 보여줍니다.
직접 명시하지 않아도 교사 모델을 닮아가는 학생 모델이 신기하다고 생각하던 찰나, 어린 아이들이 떠오릅니다. 가르치지 않아도, 아이가 어른의 행동이나 눈빛 등을 통해 세상을 배우는 것과 같은 이치겠지요. 아무리 인간의 지능을 따라하는 ‘인공지능’이라지만, 이런 모습도 유사하다니 헛웃음이 납니다. 사람도, 기계도 위가 맑아야 아래가 맑은가 봅니다.
📮 먀 AI 뉴스레터: 단순 트렌드 나열이 아닌, '진짜' 인공지능 이야기
👉🏼 구독하기: https://mmmya.stibee.com/
